Aprovechando que estamos aun cerca del dia de la contraseña, y antes de que se me pase la buena oportunidad, publico este articulo relacionado con contraseñas.
La idea con este articulo es mostrar que se puede con filtraciones hechas por cyber criminales y como sacar de lo malo algo bueno. En este caso, voy a analizar una filtración que en teoría pertenece a una organización gubernamental colombiana (que yo sepa no se ha probado realmente de donde viene la filtración), la cual, al parecer hace parte de una base de datos grande, pero solo se filtró una parte.
Primero voy a hacer una sencilla descripción de la filtración y los datos en ella contenidos, diferentes análisis sobre las contraseñas y los nombres de usuarios (Top de contraseñas, Análisis de longitud, análisis de correlación y distancia de Levenshtein) y finalmente las conclusiones.
La finalidad del articulo es poder entender mejor a los usuarios que tenemos que proteger, para así tomar las medidas necesarias y alcanzar el objetivo de proteger a los usuarios y hacer internet mas seguro.
Descripción de la filtración
Alrededor de septiembre de 2023, en un foro de la internet profunda, apareció una filtración relacionada con una entidad gubernamental colombiana, inicialmente se pensó que la filtración estaba relacionada con el incidente de IFX Networks porque fue casi al mismo tiempo, pero al final del post aparece la leyenda de abajo.
Basado en este ultimo comentario, se puede establecer que el incidente no está ligado con IFX, pero además el autor de identifico así mismo e indico cual fue la motivación detrás de esta acción. Si alguien quiere saber más de esto una búsqueda de 5 minutos en Google o 2 de chatgpt les brinda la información tanto del actor como la motivación.
Descripción de los archivos
Nota aclaratoria: La filtración llego a mis manos atreves de otro investigador, el cual no entendía bien el contexto, ni las implicaciones, así que me pidió que hiciera una valoración de esta, la información compartida en este articulo hace parte de la valoración y análisis que se hizo en ese momento.
La información consta de 6 archivos, en formato csv de poco tamaño, los archivos son:
- correos.csv: Contiene una lista larga de direcciones de correo electrónico de diferente tipo, incluyendo Hotmail, yahoo, achar y otro montón de dominios diferentes incluyendo dominios gubernamentales colombianos, tales como orocue-casanare.gov.co, novita-choco.gov.co, nimaima-cundinamarca.gov.co. Seguido de un campo en blanco y el campo Departamento, que muchas veces en lugar de decir el nombre departamento dice alcaldía o gobernación.
- perfil.csv: El archivo solo contiene tres registros, cada registro con dos campos, el primero se llama perf_id y el segundo perf_nombre. Aparentemente es una tabla donde se definen los tipos de usuario, en total 4 miserables registros en todo el archivo.
- usuarios_bsc.csv: El archivo contiene 2 registros, cada uno con dos campos.
- vta_iniciativa_usuarios: El archivo contiene 57 registros, cada registro tiene los campos enti_id, estr_id, ties_tipo, enti_nom, estr_codigo, estr_descripcion, estr_ponderacion, usua_usuariolider, usua_usuarioasesor, usua_usuariopadrino, estr_usuarioresponsableregistro; como se puede deducir por los nombres de los campos, el contenido del archivo son nombres de proyectos o de personas ligadas a este o algunos códigos.
- usuarios.csv: El archivo contiene alrededor de 800 registros, la estructura se puede ver en la imagen2.

Los archivos al parecer representan tablas de una base de datos, pero todas estas tablas no son la totalidad de la base de datos y si lo son es una base de datos bien chunga.
El archivo objeto de este artículo es usuarios.csv, el cual contiene alrededor de 800 registros que incluyen diferentes campos (Imagen3 ), de estos registros, los más relevantes para la investigación son: Nombre del usuario, username, password e email, etc.

Después de mirar por encima el archivo de usuarios, me fijo si que existen direcciones de e-mail pertenecientes a diferentes entidades gubernamentales colombianas, la mayoría son de un ministerio (con esta información se puede hablar de que existe una buena probabilidad de que la filtración si provenga de la fuente que el actor aseveró). Lo siguiente que observe, fue la fecha más reciente existente en el archivo, esta fue ubicada en el campo “USUA_FECHAMODIFICADA”, el cual se deduce que significa, la última fecha en la que se cambió la contraseña del correspondiente usuario, esta información (si el autor no la manipulo o fabrico) indica con alta probabilidad, que la información se obtuvo el 30 de agosto de 2023 o en una fecha posterior.
Acerca de las contraseñas
Después de mirar fechas y datos iniciales de los archivos, lo siguiente fue tratar de hallar datos significativos con respecto a las contraseñas, como por ejemplo, hallar las contraseñas más usadas, con este fin, lo primero que hice fue un análisis de frecuencia, para encontrar las contraseñas más usadas. Lastimosamente, el resultado no fue una sorpresa ni debería serlo para involucrados en el campo de la seguridad, porque son las mismas contraseñas que hemos visto por muchos años.
La contraseña más usada es “123456” con más de 250 repeticiones, las siguientes siete contraseñas más usadas, son las típicas combinaciones numéricas o variaciones del 12345, con más o menos cifras, el top nueve y diez de contraseñas son mintic2019* y Bogota2016 respectivamente, estas dos últimas podrían indican con buena probabilidad, la ciudad y entidad donde más se usó o se usa la plataforma de la cual proviene la información filtrada.
En la imagen de abajo, se puede ver el grafico de las 35 contraseñas más usadas (repetidas), son el “Top 35”, porque a partir de la numero 36, las contraseñas solo son encontradas una única vez.

Longitud de las contraseñas
Lo siguiente que decidí calcular fue la moda con respecto a la longitud de las contraseñas, sin tomar en cuenta el número de repeticiones de estas (cat file.csv|sort|uniq), como resultado la imagen de abajo. Este valor lo calculo con el objetivo de entender si los usuarios crean contraseñas largas o cortas, también para entender que tamaño de contraseñas serían más efectivas a la hora tanto de auditar contraseñas, como para crear diccionarios específicos para ser usados en Colombia por los equipos rojos o para hacer diccionarios de lista negra.
Este valor conjugado con otros datos (que no tengo) podría ser usado por otros investigadores para calcular, por ejemplo, si los usuarios se apegan al menor esfuerzo y solo crean contraseñas que cumplan con los requisitos mínimos de seguridad, o de pronto para un estudio sociológico y entender mejor los comportamientos de seguridad usados por los ciudadanos colombianos.
El resultado del cálculo de la moda se puede ver en la siguiente imagen:
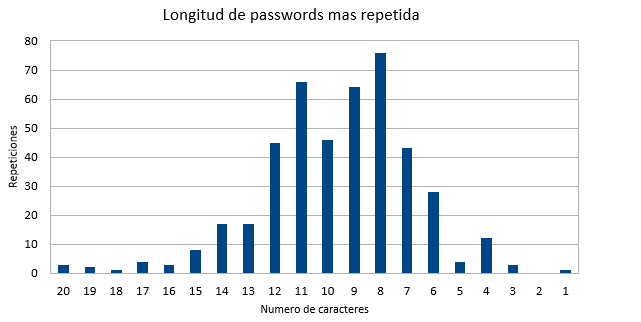
En el grafico se observar, que la mayoría de las contraseñas están en el rango de 7 y 12 caracteres, pero la ganadora indiscutible es de solo 8 caracteres.
Asumiendo que esta base de datos es representativa de la población colombiana, esta medida nos indica que a la hora de hacer auditorias que involucran contraseñas es mejor intentar primero con diccionarios de 8 caracteres, luego de 11,9,10,12….
Esta información no solo es útil para los cibercriminales, sino para el equipo azul también y para el personal encargado de concienciación de ciberseguridad, por los siguientes motivos:
- Para defender un objetivo, prohibir el uso de contraseñas menores de 12 caracteres, creando condiciones más difíciles para el atacante, tanto porque son más difíciles de crackear como porque están fuera del rango donde están la mayoría de las contraseñas.
- Para encargados de concienciación, a la hora de entrenar a los usuarios enfocarse en crear contraseñas de más de 12 caracteres, sugerir el uso de frases como contraseñas en lugar de palabras, las frases fácilmente sobrepasan los 12 caracteres y son más difíciles de generar, un ejemplo puede ser: “SoyUsuariodelMinMientrasPasa2023”. La frase es fácil de recordar porque es lenguaje natural y es larga, cumpliendo el objetivo de difícil adivinación.
Contraseñas y el tiempo
El siguiente paso, fue ver que tan relacionadas estaban las contraseñas con el tiempo, cuando hablo de tiempo me refiero, a si la contraseña incluye alguna información que pueda ser relacionada con una fecha, un mes o un año. El resultado fue el siguiente:
- 605 contraseñas no estaban relacionadas al tiempo.
- 192 incluían un año, por ejemplo 1992 o 92/6/12.
- 6 incluían solo mes o día, por ejemplo: Junio o 10/24.
Por favor, no tomar esta medida o datos como algo confiable ni estadístico, ¡porque no use ningún método confiable para medir esto! lo que hice fue buscar por años, meses y números que tuvieran algún sentido (para mi) y se pudieran interpretar como fechas.
Contraseñas y nombres de usuario
Para hacer esto, me apoye en el algoritmo de distancia de Levenshtein, el cual expresa cuan diferentes son dos cadenas de caracteres, indicando el número de cambios que hay que hacer para que sean iguales. La idea básica del algoritmo es: cuanto tengo que cambiar la cadena1, para que sea igual a la cadena objetivo cadena2, en ese momento el algoritmo cuenta cuantos caracteres tengo que agregar, quitar o modificar, este da como resultado un valor. Mientras más grande sea el valor, quiere decir que más distinto o menos similares son las cadenas entre sí, en cambio, si el número es bajo, eso quiere decir que las cadenas son más parecidas entre sí.
En el caso de Levenshtein normalizado, nos indica que tan importante o que tanto hay que cambiar la cadena, pero ya no en termino de pasos si no en términos de 0 a 1, mientras el número sea más cercano a 1, eso quiere decir que la cadena es menos similar, mientras el número sea más cercano a 0, eso quiere decir que las cadenas son más parecidas entre sí.
Ejemplo de aplicación de la distancia de Levenshtein seria:
Ejemplo 1:
- Cadena inicial=mlojas
- cadena Objetivo=mlojas30
- Levenshtein=2 (Agregar 2 caracteres, 3 y 0)
- Levenshtein normalizado=0.25
Ejemplo 2:
- Cadena inicial=Lariza
- Cadena Objetivo=lariza123*
- Levenshtein=5 (hacer cinco cambios, cambiar l por L, agregar 4 caracteres 1,2,3 y *)
- Levenshtein normalizado=0.50
Si alguno está interesado en el tema, puede buscar por algoritmo de distancia de Levenshtein, que, por cierto, hay un paquete de Python en el repositorio oficial listo para instalar y usar. Si está interesado en como medir la similitud entre cadenas de caracteres, puede buscar “The complete guide to string similarity algorithms”, en el artículo hay varios algoritmos y pues uno usa el que más se adapte a sus condiciones.
Volviendo al cuento; para usar el algoritmo previamente prepare los datos, en el caso de la dirección de email, quite la arroba (@) y el dominio, para solo dejar el nombre de usuario; otra cosa que prepare fue eliminar las contraseñas numéricas con sus correspondientes usuarios, porque al final no me aportan nada y pueden dañar los resultados. La submuestra nos quedó de 406 usuarios con sus correspondientes contraseñas.
Como resultado obtuvimos:
- El valor mínimo de Levenshtein normalizado: 0
- El valor máximo de Levenshtein normalizado: 1
- La moda del valor de Levenshtein normalizado: 1
- La media de Levenshtein normalizado:0.84475
- Valores por encima de la media:283
- Valores por debajo de la media:123
Contraseñas y direcciones de email
Como me pareció que el análisis de similitud no era tan representativo como yo había concebido (esa concepción era mental y estaba dada por mis observaciones iniciales, nada científicas de los datos), entonces decidí dejar mi BIAS a un lado y hacerlo igual, pero dejando toda la dirección de email, quitando los usuarios con contraseñas totalmente numéricas, la muestra fue la misma 406 usuarios.
Como resultado obtuvimos:
- El valor mínimo de Levenshtein normalizado:0.538461538461538
- El valor máximo de Levenshtein normalizado: 1
- La moda del valor de Levenshtein normalizado: 1
- La media de Levenshtein normalizado:0.8672
- Valores por encima de la media:228
- Valores por debajo de la media:178
Como se puede ver con los dos análisis de similitud, no hay cambios muy sustanciales, a pesar de que los valores por encima y por debajo de la media cambiaron, esto se debe a que la media de distancia de Levenshtein subió, entonces los valores que antes están por encima de la media ahora están debajo de la media.
Lo único que veo para resaltar, es que en el análisis inicial existían valores con distancia de Levenshtein de 0, ósea que el usuario y la contraseña eran iguales, pero en el segundo análisis ya no existen valores iguales a 0, esto puede indicar una tendencia entre algún porcentaje de personas a usar los nombres de usuario como inspiración para las contraseñas, más que usar el nombre de la empresa. Por las observaciones empíricas que hice al principio, vi algunas contraseñas que usaban el nombre de una entidad seguido de un número, pero sinceramente fueron muy pocas y me da pereza hacer el análisis.
Hilando un poco más fino, como muchas veces los nombres de usuario están ligados a la información personal del usuario (como su nombre propio), entonces se podría llegar a decir que hay una tendencia en un grupo de usuarios que usa su información personal o el nombre de usuario para crear sus contraseñas. Esta también es la idea o concepto que tenemos en la cabeza, pero en este análisis no hay información estadística significante que corrobore esta afirmación. En la imagen de abajo (Imagen3) se ve una lista de ejemplos, donde el usuario parece un nombre y la correspondiente contraseña es el nombre de este mismo.

Conclusiones
Para equipo Azul
- Crear políticas de contraseñas que deben ser de mínimo 13 caracteres. Asumiendo que las contraseñas generadas en Colombia son parecidas a las de esta filtración, esto reduce en gran porcentaje las posibilidades de éxito del atacante. (Todos sabemos que las contraseñas largas son un dolor de cabeza para los atacantes hasta a la hora de crackearlas).
- Implementar una lista negra para contraseñas.
- Al momento de asignar una contraseña, si la nueva contraseña está en la lista negra, pues esta no es válida.
- Si se quiere ir un paso más allá, puede usar el algoritmo de Leveshtein para analizar el email completo, el usuario o el nombre propio del usuario contra la nueva contraseña, si el índice es muy bajo, la contraseña no es válida.
- Eliminar el almacenamiento de contraseñas en texto plano. Si las contraseñas hubieran estado almacenadas en formato hash con “Sal”, otra seria la historia.
- Crear políticas de cambio de contraseñas periódicas e implementar doble factor de autenticación. Esto tiene ventajas, desde limitar la ventana de acceso hasta limitar la validez de la información filtrada.
Para concienciación de la seguridad
- Fomentar el uso de contraseñas largas, poniendo como ejemplo que puede crear frases en lugar de una palabra complicada
- Explicar los beneficios de la política de cambio de contraseñas que los usuarios odian, pero la odian porque no entienden la ventaja de cambiarla, como por ejemplo limitar la ventana de acceso de un atacante y como esto puede desmotivar a un atacante para tenernos como objetivo.
- Explicar porque no se deben usar contraseñas que estén en listas negras, muestre con un ejemplo como una contraseña de 20 caracteres que está en una lista negra puede ser “adivinada” y usada sin importar lo larga, confusa, robusta y segura que esta sea.
Para Rojo y Azul
Les dejo el link al diccionario del top 35 de contraseñas que se deriba de este articulo.
